
Introducción
En una tarde de jueves, el equipo de control de gastos decidió revisar detalladamente los costos asociados al uso de los servicios de AWS. Tenemos una aplicación que se ofrece como un servicio SaaS a nuestros clientes, lo que implica el uso de varios servicios en la plataforma de AWS. Durante el análisis, notamos un aumento significativo en los gastos relacionados con el almacenamiento en la base de datos. Por lo tanto, comenzamos a explorar alternativas para controlar este incremento y optimizar nuestros costos sin sacrificar funcionalidades.
Descripción del problema
Nos dimos cuenta de que una parte significativa del aumento se debía a datos almacenados que tenían una probabilidad baja de ser consultados, ya que se trataba de información histórica con mucho tiempo almacenada. Este incremento en los gastos se debía a que los datos históricos seguirían acumulándose con el tiempo. Ante esta situación, decidimos explorar otras alternativas de almacenamiento específicamente para los datos históricos, buscando una solución que nos permitiera acceder a ellos de manera eficiente y a la vez reducir costos.
DynamoDB
AWS DynamoDB es la principal base de datos que se utiliza en la plataforma, y este es un servicio de base de datos NoSQL. Es una base de datos de clave-valor y documentos, completamente administrada y escalable automáticamente. Está diseñada para ofrecer un rendimiento rápido y predecible en cualquier escala de trabajo. Esta base de datos, para almacenar la información utiliza un concepto llamado “partición” que no es más que un disco de estado sólido donde se persiste la información.
Modo Aprovisionado
Al crear una tabla en DynamoDB, debes especificar el modo de capacidad aprovisionada. Esto significa que debes configurar la capacidad de lectura (Read Capacity Units – RCU) y la capacidad de escritura (Write Capacity Units – WCU) que requiere tu aplicación.
- Capacidad de Lectura (RCU): Una RCU representa una lectura consistente de 4 KB por segundo.
- Capacidad de Escritura (WCU): Una WCU representa una escritura de 1 KB por segundo.
Modo a Demanda
Esta es una forma de crear las tablas sin definir la capacidad de lectura o escritura. Su capacidad se adapta de forma instantánea a las cargas de trabajo.
💡 En nuestra solución, usamos el modo aprovisionado con una cantidad de unidades de escritura y de lectura especificados para la demanda de nuestra solución, y para que los costos sean predecibles.
Estas capacidades de lectura y escritura se distribuyen entre la cantidad de particiones que tiene la tabla. Las particiones se refieren a los discos asignados a la tabla. Es crucial entender cómo el servicio asigna esta cantidad de discos o particiones a las tablas, lo cual se realiza mediante dos alternativas:
- En base a la capacidad, y esto es usando la siguiente formula:
- En base a la cantidad de los datos, y esto usando la siguiente formula:
En el caso de AWS DynamoDB, el servicio elige entre dos posibilidades para crear particiones: basarse en la capacidad o en la cantidad de datos, optando por la opción que resulte mayor. En nuestro caso, la opción era la basada en la cantidad de datos, debido a que nuestras tablas contenían una gran cantidad de datos históricos. Esto ha resultado en la generación de múltiples particiones. El problema con tener muchas particiones es que la cantidad de unidades de lectura y escritura se divide entre la cantidad de particiones existentes.
Ejemplo: Si se tiene dos particiones y se cuenta con 100 unidades de escritura para una tabla, a cada partición se le asigna 50 unidades de escritura a cada partición; esto con el fin de garantizar la posibilidad de ejecutar escrituras en paralelo o lecturas si es el caso, pero si ya una partición está llena, pues esta capacidad se ve disminuida para el ejemplo a la mitad, y esto además del costo era un problema que estaba generándonos en la plataforma. Si hay 3 particiones la capacidad se divide entre 3 y así sucesivamente…
Solución propuesta
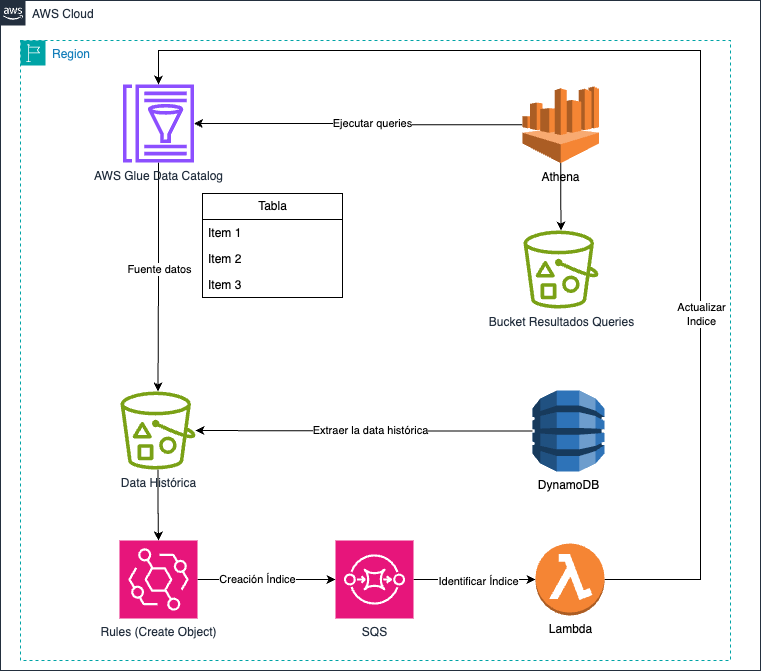
La solución implica la eliminación de los datos históricos de las tablas de DynamoDB para mejorar el rendimiento y lograr ahorros significativos. En este sentido, optamos por emplear AWS Glue Data Catalog, que nos facilita la creación de una tabla con el mismo esquema que la de DynamoDB y el almacenamiento de datos en un Bucket de S3, un servicio más rentable en términos de costos de almacenamiento. Además, aprovechamos AWS Athena para aprovechar al máximo la tabla y los datos almacenados en S3 como si fueran parte de una base de datos relacional, lo que nos permite utilizar SQL para nuestras consultas de manera eficiente y sin grandes esfuerzo de cambio (modificación de los componentes actuales para que busquen o en DynamoDB o en Athena).
Implementación
La solución combina varios servicios para extraer datos históricos de DynamoDB al Bucket, que actúa como la fuente de información para la tabla de Glue, permitiendo así la explotación de la información como si fuera una base de datos. Los datos se almacenan en formato JSON comprimido con Gzip.
Demo de Glue + S3 + Athena
A continuación se presenta un tutorial que explica cómo configurar la tabla en Glue, el Bucket de S3 y Athena. Sin embargo, el tutorial no aborda cómo está construido el componente de extracción de datos históricos.
Componente Extracción Datos de DynamoDB
El componente tiene el siguiente algoritmo
- Ejecutar una consulta en DynamoDB para recuperar los registros antiguos.
- Para cada registro, extraer el atributo de fecha y utilizarlo como parte de los índices, junto con otros elementos como se indicó en el tutorial utilizando el atributo «Id».
- Crear un JSON con cada registro obtenido de la consulta y comprimirlo.
- Guardar este archivo en el bucket respetando la estructura del índice para que la tabla de Glue pueda reconocerlo.
- Eliminar el registro en la tabla de DynamoDB
💡 Referencia al código del componente de extracción para su consulta en el siguiente link
Componente actualiza Índice
Este componente es crítico para la solución, ya que maneja una gran cantidad de datos provenientes de la tabla de DynamoDB y su transferencia al Bucket S3. Para lograr esto, es necesario actualizar la tabla en Glue Table. Hay varias alternativas disponibles para realizar esta actualización. Para más detalles, puedes consultar el siguiente artículo.
En esta solución como se ve en el gráfico, se tiene el siguiente algoritmo:
- Se ha configurado escuchar los eventos de creación de objetos en el bucket S3
- Los eventos configurados en EventBridge son enviados a una cola SQS
- Los elementos de la cola SQS son procesados por una función Lambda
La lógica de la función lambda se encuentra a continuación.
import * as AWS from 'aws-sdk';
import { SQSEvent } from 'aws-lambda';
const glueClient = new AWS.Glue();
let StorageDescriptor: any;
const concatPartitionValues = (values: any): string => {
let concatenatedString = '';
for (const key in values) {
if (Object.prototype.hasOwnProperty.call(values, key)) {
concatenatedString += `${key}=${values[key]}/`;
}
}
return concatenatedString;
};
const extractPartitionValuesFromPath = (objectPath: string): string[] => {
const pathParts = objectPath.split('/');
const partitionValues = [];
for (const part of pathParts) {
const [key, value] = part.split('=');
if (value) {
partitionValues.push(value);
}
}
return partitionValues;
};
const extractPartitionValuesWithKeyFromPath = (objectPath: string): { [key: string]: string } => {
const pathParts = objectPath.split('/');
const partitionValues: { [key: string]: string } = {};
for (const part of pathParts) {
const [key, value] = part.split('=');
if (key && value) {
partitionValues[key] = value;
}
}
return partitionValues;
};
export const handler = async (event: SQSEvent) => {
const sqsRecord = event.Records;
if (!StorageDescriptor) {
const tableGlue = await glueClient
.getTable({
DatabaseName: process.env.DATABASE_NAME!,
Name: process.env.TABLE_NAME!
})
.promise();
StorageDescriptor = tableGlue.Table!.StorageDescriptor;
}
for (const record of sqsRecord) {
const message = JSON.parse(record.body);
const bucketName: string = message.detail.bucket.bucketName;
const objectKey: string = message.detail.object.key;
const partitionValues = extractPartitionValuesFromPath(objectKey);
const partitionValuesWithKey = extractPartitionValuesWithKeyFromPath(objectKey);
try {
const paramPartitions: AWS.Glue.GetPartitionRequest = {
DatabaseName: process.env.DATABASE_NAME!,
TableName: process.env.TABLE_NAME!,
PartitionValues: Object.values(partitionValues)
};
const result = await glueClient.getPartition(paramPartitions).promise();
} catch (error: any) {
if (error.code === 'EntityNotFoundException') {
console.log('values partitions:', partitionValuesWithKey);
const partitionInput: AWS.Glue.PartitionInput = {
Values: Object.values(partitionValuesWithKey),
StorageDescriptor: {
...StorageDescriptor,
Location: `${StorageDescriptor.Location}${concatPartitionValues(partitionValuesWithKey)}`
}
};
const paramsIndex: AWS.Glue.CreatePartitionRequest = {
DatabaseName: process.env.DATABASE_NAME!,
TableName: process.env.TABLE_NAME!,
PartitionInput: partitionInput
};
const newpartition = await glueClient.createPartition(paramsIndex).promise();
console.log('indice creado:', concatPartitionValues(partitionValuesWithKey));
}
}
}
};
Consideraciones
Fue crucial buscar reducir los costos asociados con el almacenamiento de la base de datos en DynamoDB y mejorar los tiempos de respuesta. La solución se basa en utilizar el servicio de S3 como fuente de almacenamiento, desempeñando un papel importante. Además, nos basamos en un enfoque asíncrono para garantizar que la tabla en Glue contenga todas las particiones necesarias (no usar el crawler por lo caro que podría resultar), evitando costos adicionales por actualizar la tabla en Glue.
Conclusiones
La reducción de costos en DynamoDB debido al cambio ha generado ahorros del 25%, lo que representa una mejora significativa en términos de costos. La automatización también ha mejorado los tiempos de respuesta para los datos históricos, y el costo asociado al cambio no fue significativo.
En este post no se está abordando la automatización que tiene que ver con evitar el exceso de datos históricos una vez extraídos de la tabla actual de DynamoDB. A un nivel más alto, lo que se tendría que hacer es que la misma tabla de DynamoDB elimine de forma automática un registro cuando se considere histórico (por ejemplo, cuando la fecha de creación del registro supere un año de antigüedad). Esta eliminación debería generar un evento para que una función lambda, por ejemplo, copie ese registro eliminado y lo envíe al Bucket para cambiar la ubicación de la información (Bucket de los datos históricos).
¿Qué otras consideraciones encontrarían Uds.?
Deja un comentario: